Joan Tafoya, a Global Operations Director for Meta, shares her successful leadership experience on a recent strategically important project and operations science’s strong contribution to her success.
Operations Science is often summarized as the interaction between demand and production and the variability associated with those elements. In a shop floor, service, or construction site tactical application this definition certainly works. There are inputs, outputs, feedback loops, buffer options of all sorts; in short, these are physical systems. Less well understood is that operations science also applies in virtual or knowledge systems such as design or project management. Even more problematic is that the power of operations science can be squandered, and much waste and unnecessary stress created, by leaders who do not integrate the science into their leadership efforts, whatever the system.
At Meta, we have been responding to enormous increases in compute power requirements driven by emergence of AI-related technology. Recently, operations science proved invaluable in my role guiding rapid implementation of thousands of Grand Teton AI platform units.

Operations science defines the relationships between buffers—capacity, inventory, and response time—and variability. Applying operations science methods and techniques to day-to-day production or knowledge work can help your organization improve performance and make a measurable, positive impact to the bottom line.
I want to share with you that executive leaders can also apply operations science thinking at their level to dramatically increase their organization’s focus and output. I call this a leadership operating system; this too is a system of inputs, outputs, feedback loops and buffers and is most successful when leveraging operations science methodologies.
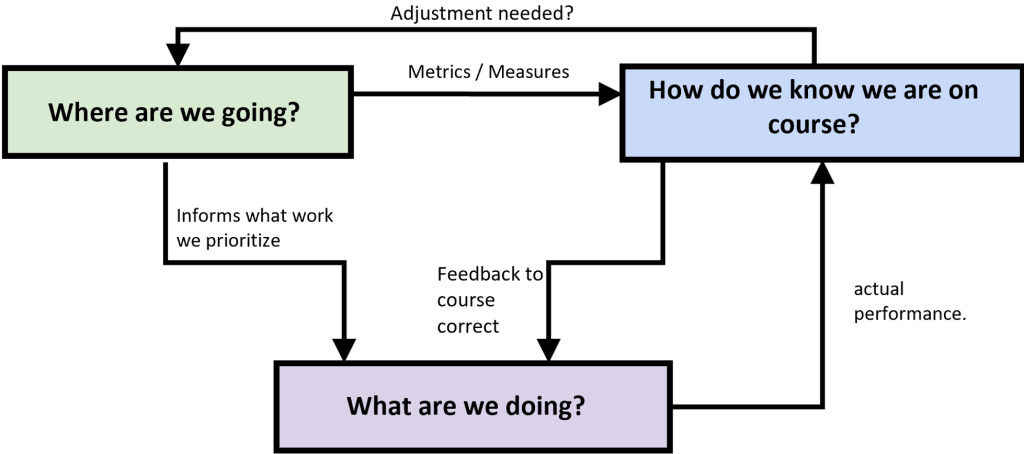
There are three questions to get us started
1. What is the goal? / Where are we going?
2. What are we doing today to get there
3. How do we know we are on course?
Let’s break these down a bit.
1. What is the goal?
Clear alignment on where a team is headed is important for a group of people to work together to be successful. It can be as specific as produce 1 million widgets a year or keep critical equipment up 99% of the time, with no downtime event longer than 1 hr. It can be more open ended to be something like: grow our business by 25% in the next year.
Besides making a statement about where we are going, a few other elements are needed. These include:
— metrics and indicators to enable predictive control and demonstrate we have met the goal
— primary work processes well documented and followed, as all work gets done through a process. This work is the work-in-process inventory buffer.
— resource allocation and prioritization methods leveraged as we need to know who is going to work on this goal, what will they start doing, continue doing, and stop doing? This is design and control of the capacity buffer.
2. What are we doing today to get there?
Of course, this starts with just doing the work: design, develop, and deliver on what is needed to reach the goal. In addition, this part of the system also includes:
— communicate to stakeholders what you are doing and why. Great work not shared really isn’t complete.
— develop the people, skills, and capabilities, for the work that needs to be done today and in the future.
— continuously improve how we work with structured, systemic problem solving.
3. How do we know we are on course?
It is not uncommon to find ourselves “heads-down” in doing the work and addressing the many urgent items filling our time every day. To combat the tyranny-of-the-urgent, and knowing that we do not work in a perfect world, it is important to build a way to monitor and control our progress. This looks like:
— monitoring the processes that are used to do the work. Are they being followed? Are they leading to expected output?
— diagnosing deviations (variability). It is important to know when we are out of standard or not getting the output we want.
— taking corrective actions. When do we ask for help? When do we escalate? How do we get our plan back on track?
These three questions are highly connected and represent a system with feedback loops, delays, and buffers as illustrated below.
Let me share an example of how this was recently used in the data center world at Meta.
1. Where are we going? Our goal was to install and maintain at high availability many thousands of units of the Grand Teton AI platform in our data centers by the end of 2023. We had standard processes for our current compute platforms, and we knew that the new AI platforms were a priority for the company. As such, we intentionally deprioritized other work and moved people over to this initiative. (capacity design and control)
2. What are we doing? The actions (our work in process inventory) we took each day included modifying our process workflows to account for AI racks of servers, which are very different from compute or storage racks, and teaching the workforce how to service and maintain NVIDIA GPUs in this configuration. Key metrics and data we generated from this included how fast we could install and provision the servers, the available time to serve traffic, reasons the servers went down, time to trouble shoot and repair, parts replaced, and more. This was a big learning experience for us as the metrics we used previously were not comprehensive enough now. GPUs are typically used in large training and inference clusters that are highly dependent with one another. The discrete nature that we were accustomed to with compute and storage hosts was no longer viable in our new AI world.
3. How do we know we are on course? We closely monitored the install pace of our new GPU systems and the performance of these systems. With respect to the install pace (our throughput and capacity utilization), the new workflows required frequent monitoring and then adjusting, really many micro improvements, to ensure we could bring on the many GPU hosts in the aggressive schedule that was committed to. As the hosts came online, daily reviews occurred to ensure the performance was as expected. Early performance did not meet expectations, but this informed new repair flows that changed how we worked
In the end, we met the committed timelines and the operational performance improved at the pace needed to meet the larger corporate goals of launching AI supported products. Thinking about the leadership operating system gives an organization a good footing to both reach the goals a leader sets out to achieve and to sustain the performance for the long term, creating a new baseline to build on.
Though the diagram below is a simple, first order illustration, a team leveraging these concepts can fully exploit the power of it by employing operations science techniques and methodologies. Some operations science practices that worked very well for me and the project team included
— Manage buffers to effectively address variability
— Deeply understand the cause and effect of metrics and measures in the systems
— Perform structured experimentation to improve work and target it more effectively to reach the goal
The leadership operating system may look something like this:
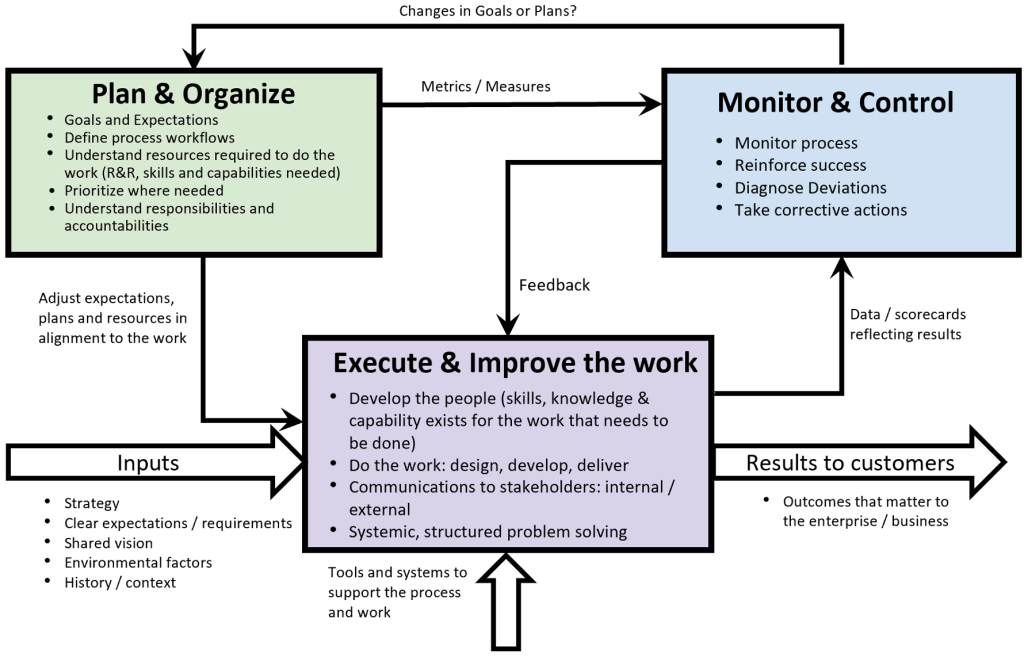
On reflection, the operations science concepts and practices were key factors in successfully leading this important strategic project for Meta. Operations science is not an ivory tower, complex technical undertaking for leaders. It provides practical, quantitative insight to help leaders rally and focus their teams using a powerful, objective framework describing operations behavior whether the operations are project leadership as described here, traditional manufacturing, services, or any type of operations.
Contact the Operations Science Institute (opscience.org) today to find out how to best leverage the science for your leadership efforts.

Joan Tafoya is Director of Global Data Center Operations for Meta and a founding member of the Operations Science Institute’s Board of Advisors.
She has applied operations science concepts successfully as part of her long, distinguished career. The Society of Women Engineers recognized Joan with its Global Leader Award in 2015 and she is an appointed fellow of the Institute of Industrial and Systems Engineers. Joan currently serves on the Albuquerque Regional Economic Alliance Board.
The Operations Science Institute provides organization development and coaching for leaders and workers in all organizations at all levels. Operations science principles and applications provide the practical science to cut through complexity, reduce conflict, and unite efforts to accelerate performance of any organization’s operations. For more information, contact Ed Pound at espound@opscience.org